
A nivel celular, todos utilizan la misma excelente base de datos genéticos para controlar su apariencia, así como también cómo se desarrollan, funcionan y se comportan.
Este conjunto de información increíblemente complejo está codificado en la molécula de ADN existente en cada célula de cada organismo. El ADN es efectivamente el manual o modelo que contiene toda la información esencial e instrucciones en forma química para construir, hacer crecer y mantener un ser vivo.
En este momento, estamos en un viaje de descubrimiento para descubrir más de los secretos guardados dentro de la estructura microscópica del ADN. Es un área de investigación que tiene enormes posibilidades potenciales para todos nosotros; todo, desde aumentar la producción de alimentos hasta ayudarnos a comprender, diagnosticar, tratar y curar una serie de enfermedades.
¿Por qué estoy particularmente interesado? Porque Linux y High Performance Computing (HPC) son tecnologías habilitadoras clave detrás de todas las investigaciones y avances en este campo.
La era de la investigación genómica.
Toda nuestra información genética se transporta en dos cadenas de ADN (ácido desoxirribonucleico) que se enrollan entre sí en forma de doble hélice. Francis Crick y James Watson identificaron por primera vez correctamente esta estructura molecular en 1953. Pero no fue hasta la finalización del Proyecto del Genoma Humano en abril de 2003 que toda la información genética en el genoma humano (una palabra técnica para todo nuestro ADN) fue identificada, secuenciada y mapeada con éxito.
Este vasto proyecto de investigación científica internacional tomó un total de 13 años y costó aproximadamente $ 2.7 mil millones para completar. Eso no es sorprendente, porque el ADN es una sustancia sorprendente y complicada.
Han pasado solo 17 años desde que se completó el Proyecto Genoma Humano inicial. En ese tiempo, el costo y el tiempo necesarios para secuenciar un genoma humano parcial o completo se han reducido. Hoy en día, las pruebas genéticas se han convertido en algo común y a menudo se pueden completar en cuestión de semanas.
Esto significa que ahora podemos mapear fácilmente el genoma de cualquier individuo para permitir un tratamiento médico más preciso. También hace posible construir y mantener bases de datos profundas y amplias de información genética del mundo real. Con este nivel de big data, podemos comenzar a automatizar el análisis a gran escala de información genética que ayuda a mejorar la atención médica para poblaciones enteras.
Mis claves para llevar
No hay duda al respecto. Estamos viviendo tiempos increíbles. Aquí hay algunos pensamientos de despedida con los que me gustaría dejarte:
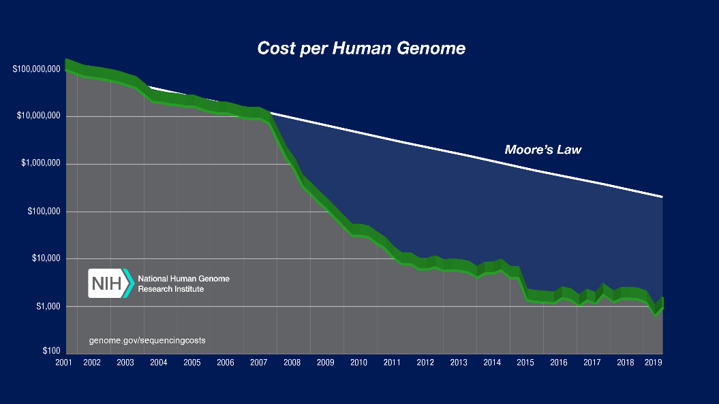
Fuente de la imagen: Instituto Nacional de Investigación del Genoma Humano
Hay dos razones para esto. Uno se debe a los avances en los métodos de secuenciación de genes, con más automatización y mayores rendimientos. El otro se debe al rendimiento y la economía enormemente mejorados de las supercomputadoras. La opción más rápida de hoy es rendir 85 veces más rápido que cualquier opción disponible hace una década. Y cada uno de los 500 principales ahora se ejecuta en Linux, lo que garantiza que sea mucho más rentable.
SUSE lidera el camino en la adaptación de Linux para entornos HPC. ¿Por qué no tomarse un momento para consultar la información disponible en cualquiera de estos enlaces?